Gideon Taylor is thrilled to announce the latest release of our enterprise-grade chatbot, Ida 24.01, marking a significant leap forward in Ida’s AI-driven communication. This update introduces a suite of enhancements designed to refine user experience, streamline administrative tasks, and, most importantly, unveil our groundbreaking T2 Ida algorithm. Let’s dive into the highlights and features of this exciting new release.
Highlight: The T2 Algorithm
At the core of Ida 24.01 is the beta release of the T2 Ida algorithm, a game-changing enhancement that sets a new standard for AI chatbot performance. This algorithm is not just an upgrade; it’s a foundation for the future, offering:
Speedier Training: T2’s advanced architecture allows for rapid model training, significantly reducing the time to deploy or update Ida’s capabilities.
Enhanced Performance: With improved efficiency, T2 ensures that Ida responds more swiftly and accurately, enhancing user interactions.
Better Accuracy: T2’s refined algorithms deliver superior understanding and response accuracy, elevating the user experience to new heights.
Reduced Rebuilds: The need for frequent AI model rebuilds is minimized, thanks to T2’s robust and dynamic architecture.
Improved NLP Capabilities: Featuring enhanced out-of-domain understanding and increased context awareness, T2 offers a more intuitive communication experience.
What’s New in Ida 24.01
Ida 24.01 is packed with features and improvements that build upon our commitment to delivering exceptional AI chatbot solutions. Here’s what you can expect in this latest release:
Student Reminder Intents with Ida Alerts: We’ve integrated new Ida Alerts for student reminder intents, ensuring timely and relevant notifications.
HCM Address Type Configuration: Administrators can now control which HCM address types are available for chat, offering more customization and relevance.
T2 NLP Algorithm: The star feature, our new T2 NLP algorithm, is now available in beta, offering a new level of performance and accuracy.
Enhanced FAQ Editor: Fixed the ability to open links in a new window directly from the FAQ editor, improving content accessibility.
Print-Aware Chat Icon: The chat icon on web interfaces now automatically hides when pages are printed, ensuring cleaner printouts.
Draggable Web Channel Icon: Enhancing user interaction, the web channel icon is now draggable, allowing for a more personalized interface.
Updated Class Schedule Integration: We’ve upgraded the data source for class schedule integrations, ensuring a more complete set of information.
Dynamic Hello Response: Ida now dynamically uses Suggestions configurations for the hello response, providing a more tailored user interaction.
Bug Fixes and Improvements:
Resolved an infinite loop issue.
Fixed visibility of inactive questions in Help or Suggestions.
Addressed an issue with incorrect utterance reporting in edge cases.
Enhanced the relevance and precision of the disambiguation list.
Improved disambiguation triggers and breakout behavior in DA setups.
Introduced the ability to randomize attention-grabbing slide-outs on the web channel.
Enhanced the relevance of disambiguation suggestions, ensuring more accurate responses.
The release of Ida 24.01 is a step in Gideon Taylor’s vision for giving your enterprise a voice with innovation and excellence in AI chatbot technology. With the introduction of the T2 algorithm and a host of enhancements, we’re setting new benchmarks for what enterprises can expect from their AI interactions. We’re excited for our clients to experience these advancements and look forward to their feedback as we continue to refine and evolve Ida’s capabilities.
The latest release of Ida, version 23.04, brings a suite of enhancements and new features to our cutting-edge digital assistant platform and is now generally available. This release focuses on improving scale with Generative AI and expanding the utility of Ida in diverse operational environments.
Spotlight Features
New Generative AI Knowledge Parser: The release introduces a groundbreaking generative AI knowledge parser. This innovative feature allows Ida to read files, urls and text and parse through the content, extracting relevant information seamlessly. This enhancement not only improves the efficiency of information retrieval but also ensures that the most accurate and relevant data is presented with guardrails.
Enhanced Small Talk Capabilities: With the new small talk setup, Ida’s natural language processing (NLP) capabilities are now more refined. This improvement leads to less false routings due to smalltalk configurations.
Configurable Recommendation Engine Frequency: To enhance the relevance and precision of the recommendation engine, its frequency is now configurable. This allows for a tailored experience where recommendations feel more organic and less intrusive, enhancing the overall user experience.
Full Feature List
Here’s a summarized list of all the features, enhancements, and fixes included in the Ida 23.04 release:
Updated user templates for Ida console access
New generative AI knowledge parser
New small talk default setup for improved NLP performance
Added effective dating of greeting text
Recommendation engine frequency is now configurable
Optimization of archive file storage locations
New default schedules and recurrences are set for all batch processing
Improvements made to small talk matching for greater accuracy (Beta)
Ida Console KPI Tiles now support federated mode
Improved support for multi-skill DAs in the KPI tiles
Fixed an issue where sometimes duration analytics were inaccurate
Fixed an issue with smalltalk datetime stamp inconsistencies from ODA
Simplified FBL Rating Page
Fine tuning of NLP algorithms
This release reaffirms our commitment to leveraging Generative AI to deliver a sophisticated and user-friendly digital assistant that evolves continuously to meet the dynamic needs of our clients. Stay tuned for more updates and improvements as we continue to push the boundaries of digital assistance technology.
Part II of our series on Generative AI (“GenAI”) expands on Part I: Top 7 Generative AI Misconceptions. In the last year, GenAI has become a focal point of both fascination and skepticism. To fully appreciate its impact, it’s crucial to understand how it diverges from Traditional AI. This post delves into those distinctions, addressing seven common inquiries from clients implementing conversational AI—ranging from chatbots to sophisticated digital assistants.
📖 For those new to AI, click here to review a few pivotal terms…
LLM (Large Language Model): An extensive model trained on diverse public data sources, featuring billions of parameters. It requires months of training and significant financial resources to operate. The aim is to simulate a broad linguistic comprehension. However, akin to a precocious teenager, an LLM grasps fundamentals but can occasionally fabricate responses. GenAI leverages the vast datasets inherent in LLMs.
Domain: This refers to a specific field of expertise. IT support (like password resets or hardware servicing), HR inquiries (such as leave balances or timesheet approvals), and financial tasks (reviewing invoices or processing expense reports) represent different domains.
Prompt: The set of instructions conveyed to an LLM in natural language. A prompt guides the bot not just on the content of the response, but the manner of its delivery, encompassing all relevant rules and parameters.
RAG (Retrieve, Augment, Generate): A technique where domain-specific knowledge is sourced and integrated into an LLM prompt, culminating in a refined, contextually informed response.
Armed with these definitions, let’s explore how GenAI stands in contrast to its predecessor, Traditional AI, through the lens of practical applications and client-driven concerns.
Traditional AI vs. Gen AI
Traditional AI is a trained model for a specific task or domain thereby sometimes called “Narrow AI”. Every output is known and approved in Traditional AI so the AI will not answer questions out of its domain. Generative AI (GenAI) is different in that it is not trained by the customer, rather it is trained by a vendor on a public data set and is meant to answer broadly a much larger set of questions. While Traditional AI has curated outcomes, GenAI uses word sequence probabilities to generate answers. Generative is a bit misleading in that it doesn’t create completely new outputs, it simply takes previous examples and shuffles them around.
Traditional AI
Generative AI
Implementation Effort
✅
Lower Software Cost
✅
Analytics
✅
Control
✅
Breadth & Scale
✅
Ongoing Effort
✅
✅
Predictability
✅
Security
✅
Run-time Speed
✅
Gideon Taylor’s Scorecard for Traditional AI vs. Generative AI
Ultimately, a hybrid approach may be the most pragmatic path forward, combining the reliability of Traditional AI for core, sensitive tasks with the adaptive prowess of Generative AI for more general inquiries.
There is great curiosity over which AI to use in which situation. Since our readership is made up of enterprise use cases, we will focus on those and specifically around user support chatbots in enterprises, higher education institutions and public sector organizations. This post aims to compare Traditional AI vs. Generative AI using the key questions our clients are asking us.
#1 – What Data does it need?
Understanding the data requirements for AI systems is key to implementing effective chatbots and digital assistants. Here’s a breakdown of the types of data needed for Traditional AI versus Gen AI:
Traditional AI
Training Data Traditional AI operates on a foundation of examples, where inputs (like user questions) are directly linked to their intents. For enterprise-level chatbots, this means preparing a dataset with a mixture of synthetic data, crafted by data scientists, and authentic interactions from users. These inputs are then mapped to predefined, curated answers, with the AI learning to recognize and respond to variations of queries within the trained domain.
Domain Data The responses in Traditional AI must be crafted and validated by humans. This guarantees that the chatbot responds correctly, following explicit guidelines. For example, in an HR service scenario, every potential query about hiring practices is paired with a corresponding, verified response.
This doesn’t mean answers cannot be automated, but the AI will have clearly defined instructions as to how it provides any given answer.
Gen AI
Training Data Gen AI starts with an extensive understanding of language, courtesy of the LLM’s training on vast and varied public datasets. This eliminates the need for organizations to create training data. However, fine-tuning with organization-specific data is an option, albeit an expensive one. The trade-off with fine-tuning involves cost and the risk of exposing sensitive data. Instead, Gen AI tends to rely on enriched prompts, utilizing the RAG method to generate responses.
Domain Data To tailor Gen AI to a particular domain, your unique organizational data is overlaid at the time of the prompt. Unlike Traditional AI, Gen AI doesn’t need an array of examples but does require high-quality, consistent, and current policy information and/or enterprise data to inform its responses. This means your effort is in curating policies which are timely, accurate and high-quality. There should be no contradictions in the data set.
#2 – How is the AI Implemented?
Implementing AI for conversational interfaces varies significantly between Traditional AI and Generative AI (Gen AI), each with its own set of procedures and challenges.
Traditional AI
The process begins with identifying the scope of queries the bot should answer, often derived from FAQs, customer support tickets, and data analytics. The next step involves creating training data for each identified question. This data synthesizes real and synthetic examples, which the AI uses to learn. Finally, answers are crafted and curated. Each of these steps can require domain experts and/or data scientists to ensure accuracy and relevance.
Gen AI
Gen AI deployment in the enterprise is centered on the Retrieve, Augment, Generate (RAG) approach. It starts with gathering domain-specific knowledge and ensuring that this information is accurate, up-to-date, and of high quality. This curated knowledge is then used to enrich prompts that guide the Gen AI’s responses. Unlike the discrete answer curation in Traditional AI, Gen AI relies on an extensive base of documents and policies to draw from, highlighting the importance of the adage “garbage in equals garbage out.” Similarly, domain experts are needed to manage this knowledge.
#3 – How does it handle security?
The security of AI-driven responses is a critical aspect, especially when sensitive information is involved.
Traditional AI
In Traditional AI, security is implemented through predefined rules that determine the sourcing and sharing of answers. Because each response is based on explicit instructions, there’s a high level of confidence in the system’s security. For instance, in environments with varying information access, like different labor unions or educational levels, Traditional AI can provide persona-specific answers. Administrators have the advantage of complete visibility and control, ensuring responses are securely tailored and compliant with organizational protocols.
Gen AI
Security in Gen AI is more complex due to the dynamic nature of response generation. While it can incorporate persona-specific policies, there’s less certainty about the precise output, as it’s generated in real-time. Despite attempts to tag policies for specific personas, Gen AI might not always adhere to these when generating responses. This has raised valid concerns regarding the use of Gen AI in contexts where strict security filtering is crucial. For example, tests have shown that Gen AI may not consistently reference the intended policy documents, potentially leading to breaches in confidentiality or incorrect information dissemination.
#4 – How does it handle out-of-domain questions?
Addressing questions outside the trained expertise is a common challenge for AI systems, handled quite differently by Traditional AI versus Gen AI.
Traditional AI
Traditional AI operates within a defined set of parameters. When faced with out-of-domain queries, it typically lacks the confidence to provide an accurate answer and is programmed to offer a polite deflection, such as an apology or a redirection to human assistance. This conservative approach minimizes the risk of providing incorrect information.
Gen AI
In contrast, Gen AI will venture a response based on the LLM’s expansive understanding of language, regardless of the domain. This can be beneficial for general inquiries but poses a risk when the question falls outside the organization’s policies or the AI’s trained expertise. In such cases, Gen AI might produce responses that are distracting, potentially inaccurate, or even in violation of workplace policies.
NOTE: Some LLMs allow you to instruct the bot to not attempt to answer out-of-domain questions and perform more like traditional AI. In our early testing at the time of this post, that setting only sometimes works.
#5 – How does the AI learn?
In order for your AI to learn and get better over time an understanding of the different learning mechanisms is required.
Traditional AI
Traditional AI learns with new training data. This data can improve understanding or even teach the AI about new knowledge, like a policy. The training data comes by way of humans or autonomous software decisions. The AI doesn’t get better unless its data and corpus of outcomes gets better.
In the case of our own Ida product, most clients allow the software to autonomously supplement training data while the team is actively filling knowledge gaps. Our clients will train the model every 2-4 weeks so that the AI is constantly getting better.
Gen AI
Gen AI learns in a few ways, the first being retraining of the LLM that exists beneath the Gen AI. This is very expensive, but the cost is bore by the LLM provider and usually is retrained a few times a year. Because training happens infrequently, the LLMs understanding is based on older information.
While not traditional machine learning, the RAG method can improve over time as the knowledge it sources improves. When inconsistencies and inaccuracies are reduced in the source data or content, the RAG element will produce better prompts thereby producing answers that feel better, even if not done by way of AI learning.
#6 – What analytics should I expect?
Monitoring usage and effectiveness of the AI is important to continual improvement.
Traditional AI
Imagine a well-organized filing cabinet. Each outcome by traditional AI is cataloged, allowing a clear understanding of how the AI reached its conclusion. This transparency allows for in-depth analysis of user queries, AI confidence levels, AI reasoning and the decision trail.
Analytics extend beyond individual interactions to include insights into data such as:
User Behavior: Time of day, location, frequency, channel usage and other trends around user behavior.
Knowledge Trends: Popular topics, questions and seasonal usage of different types of information.
AI Performance: Knowledge areas the AI feels very confident or less than confident to identify where knowledge gaps exist or AI performance needs to be examined.
Gen AI
In contrast, generative AI operates more like a magician’s hat. While it delivers impressive results, the inner workings remain largely shrouded in mystery. We see the user’s query and the AI’s response, but the process of generating the response remains a black box.
This lack of transparency presents several challenges for analytics:
Limited Insight: We have minimal understanding of the factors influencing the AI’s output.
Difficult Optimization: Without insight into the decision process, it’s challenging to improve the AI’s performance.
Uncertain Trust: The lack of transparency can lead to concerns about bias and fairness in the AI’s output.
#7 – How is the AI Maintained?
The maintenance of AI systems is critical to their effectiveness and accuracy, with practices differing significantly between Traditional AI and Generative AI (Gen AI).
Traditional AI
The upkeep of Traditional AI involves regular analysis of user interactions to identify and address knowledge or comprehension gaps. This means continually feeding the system new data, which includes questions, answers, and enriched training data to improve its understanding and response accuracy. Retraining with this updated information helps the AI expand its capabilities and adapt to changes in user behavior and language. Additionally, it’s essential to periodically review and update existing answers to reflect any changes in policies or information.
Gen AI
Since the training of Gen AI’s LLMs is not typically handled by individual users or organizations (unless fine-tuning is applied), maintenance focuses on enhancing the prompts used in the RAG method. To address new topics or refine understanding, the knowledge base used for prompt enrichment must be updated. Maintenance for Gen AI also includes ensuring the information used for responses remains current and precise, necessitating regular content reviews and updates.
Conclusion
Traditional AI offers a controlled environment with predictable outcomes and robust security, making it suitable for scenarios where precision and reliability are paramount. Its maintenance and learning processes, though requiring more effort, provide a level of transparency and control that can be critical for sensitive or highly regulated domains.
Generative AI, on the other hand, offers versatility and the ability to handle a broader range of queries. Its ability to generate responses from a vast corpus of language data can provide advantages in terms of answering more questions with less effort. However, the challenges associated with its black-box nature, potential security concerns, and the need for high-quality domain data for accurate responses must be carefully considered.
Below we will illustrate major features of any AI and whether Traditional or Generative AI has an advantage.
Traditional AI
Generative AI
Implementation Effort
✅
Lower Software Cost
✅
Analytics
✅
Control
✅
Breadth & Scale
✅
Ongoing Effort
✅
✅
Predictability
✅
Security
✅
Run-time Speed
✅
Organizations must weigh these factors against their specific use cases, resources, and risk profiles. Ultimately, a hybrid approach may be the most pragmatic path forward, combining the reliability of Traditional AI for core, sensitive tasks with the adaptive prowess of Generative AI for more general inquiries. This is exactly the path Ida is taking. Such a strategy can harness the strengths of both systems while mitigating their individual weaknesses, leading to a robust, dynamic, and efficient AI implementation. If you have any questions or need help in your AI project, don’t hesitate to contact us.
Gideon Taylor is pleased to announce our participation in The Tambellini Group’s Future Campus™ Summit in Newport Beach, CA January 17-18, 2024. We’re also excited to share that our CEO Paul Taylor and IntraSee co-founder and Managing Director Andrew Bediz will be discussing how to avoid “analysis paralysis” when implementing Artificial Intelligence in a Higher Ed environment during a plenary session at the Summit. Please join us!
In the burgeoning field of Generative AI, misconceptions are as common as the vendor emails flooding your inbox touting it as the panacea for modern business woes. Is that amazing demo you saw real? Is it ready for production use? How much time and money will it take? In this blog, we’re setting the record straight on the myths prevalent in today’s discourse, particularly from the perspective of enterprise customers using chatbots to understand language and produce answers.
Understanding Traditional AI
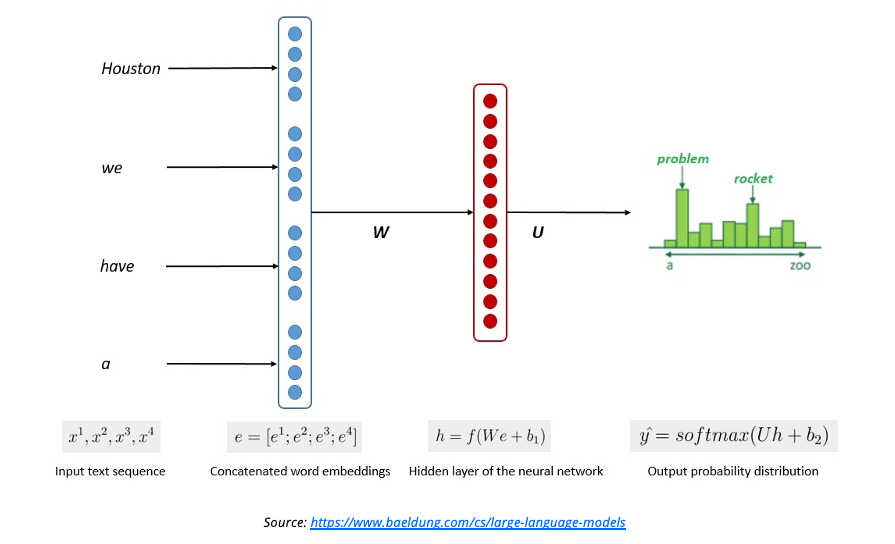
Before we examine Generative AI, it is important to understand traditional machine learning AI and how it differs from Generative AI. ML/AI works by imitating the human brain through a digital representation of the brain’s neural network. In short, it establishes groupings of patterns that allow it to handle an input it has never seen before and produce the expected output.
These models are trained by giving the AI examples of inputs and the expected output. The model can then use inference to determinewhich output should be delivered. In natural language processing (NLP), these inputs are mapped to Intents, and every Intent is defined separately, along with the output the Intent should generate.
How is generative AI different?
Generative AI popularized by models such as GPT diverges from predefined intents and outputs, instead generating responses in real-time based on vast training datasets and complex word-order probabilities. The magic of Generative AI isn’t sorcery but sophisticated mathematics. To do Generative AI well, large language models (LLMs) train billions of parameters at a cost of up to $100 million per training pass. As such, no organization looking to use Gen AI for their internal operations will take that cost on themselves; rather, they will just pay a Gen AI provider to use their model. Because Generative AI is intentless, meaning you don’t have to explicitly set up a list of questions it can answer, many believe it is a way to hyper-scale the outputs an AI chatbot can support.
The big challenge with using Gen AI to power an enterprise chatbot is that you can’t train it on your own enterprise data, because the training passes are so expensive. The most effective strategy to get around this limitation involves the RAG (Retrieve, Augment, Generate) method. This approach initially retrieves pertinent data from your enterprise databases or other sources. Subsequently, it enriches the Large Language Model (LLM) prompt with this information, aiming to guide the model towards generating responses that are not only relevant but also confined within the parameters of the enriched prompt. You’re effectively asking the LLM, “Considering the huge public dataset you’ve already been trained on, but also considering this small private dataset I’m giving you now, please answer this question.” This technique ensures more targeted and accurate output, leveraging the strengths of LLMs while maintaining cost-effectiveness.
Misconception #1: Generative AI can answer any question flawlessly
The belief that Generative AI is infallible is the first fallacy. Gen AI isn’t concerned about being right or wrong. It is just generating word sequences based on patterns in the data it is trained on or prompted with. Because that data is human-derived and humans are imperfect, Gen AI is equally imperfect. Therefore, should we accept this imperfection? AI is a means for automating what humans do, so if the AI is imperfect, but less so than the humans, does it matter? If the AI produces a better outcome more often, does it have to be perfect?
The challenge lies in the lack of administrative control around what is produced coupled with the tone of answers giving the impression of confidence, even when incorrect. The AI doesn’t actually understand either its own training data, or the questions it is asked; even so, it has been trained to generate confident, authoritative-sounding answers. It can therefore generate convincing answers that are spectacularly, even dangerously wrong. These are referred to as hallucinations.
Misconception #2: Generative AI is plug ‘n play
ChatGPT is based on public knowledge like Wikipedia and took years of training with thousands of human hours in supervision. Using a public model like GPT, or even the enterprise edition of a Large Language Model, doesn’t simply just plug in and work. Despite the marketing shine, Generative AI does not operate independently with its own intentions. These large models are tools that operate within the constraints set by their developers and the data they were trained on. When used in the enterprise, that data needs to extend well beyond Wikipedia to things like HR records, policy documents, procedures and more. Who identifies, curates, maintains, and updates this data and ensures it is timely, error-free and high-quality? That is right, you do.
While Generative AI can produce wonderful results, it is not without human effort to implement and maintain.
Misconception #3: Generative AI understands better
Generative AI-based chatbots are often compared to older, poorly-trained AI chatbots without generative capabilities. People often believe that generative AI truly ‘understands’ the content it generates. In reality, these models don’t understand content in the human sense. They analyze patterns in data and replicate these patterns to generate new content. In other words, Gen AI is just rephrasing your existing, human-written policy, not truly coming up with unique answers. If your policies have gaps, errors or omissions, then the answers generated will be equally bad.
There are no shortcuts when your data/knowledge quality is poor.
Misconception #4: Generative AI can easily be used in the enterprise
Incorporating Generative AI into enterprise settings is not without its challenges. Issues of privacy, security, and the risk of data leakage loom large. Solutions involve dedicated, isolated models that are considerably more costly, raising questions about practical widespread enterprise use.
The solutions to these concerns are currently 1) training your own model in your own tenancy (exponentially more costly), 2) fine-tuning an existing LLM (also very costly though less so than #1) and 3) using a RAG method where enterprise data is piped into the process via prompts (though questions of accuracy and data leakage persist).
Further, the answers generated are not guaranteed to be accurate. While there are techniques to guardrail the responses, they don’t perform at 100%. Are there unknown liabilities of generating answers that may, at times, be inaccurate? As of this post (Nov 2023), one such issue was found by Gregory Kamradt which shows GPT4 with 128k context not being able to deliver answers based on the facts in large policies (which are quite common for big enterprises). https://www.linkedin.com/feed/update/urn:li:activity:7128720460170625025/
The data security, the costs, and the unknown liabilities all make using Generative AI in the enterprise layered and complicated.
Misconception #5: Generative AI is a machine, therefore without bias
The impact of data bias is often underestimated. Generative AI can—and often does—propagate the biases present in its training data, leading to outputs that may reinforce existing prejudices. Leveraging an existing large model will be based on a large dataset usually from public sources such as Wikipedia, Reddit, etc. Because that data was originally created by humans, their bias can be embedded in the data and influence the output of Gen AI. To be fair, talking to a human also results in bias, so this doesn’t mean avoiding Gen AI is the answer. Rather, one just needs to be aware of the risks of building their own model vs. using someone else’s model.
The dilemma lies in whether to use a pre-trained model, with its inherent biases, or invest in developing a bespoke model, often at prohibitive expense.
Misconception #6: Generative AI can learn and improve on its own
A common myth is that AI can autonomously learn and improve post-training. In truth, without new data or retraining, an AI’s knowledge becomes stagnant. Continuous human intervention is necessary to update and refine these models. Even using a RAG method with Gen AI requires the humans to feed the AI updated information in order to improve outcomes.
There are no shortcuts or magic in AI. It’s all about timely, high-quality, evolving data.
Misconception #7: Generative AI is affordable
Text-based Generative AI depends on Large Language Models. In the case of GPT, those models take months to train and can use $100M in compute power. Every call to an LLM like GPT is metered by a few pennies per a bundle of tokens. A token is basically the equivalent of a 5-character word. Every word input and output gets charged, but also the entire history of the conversation is reposted during each subsequent message, meaning longer conversations incur the initial cost of knowledge seeding at every press of the enter key. A recent study by Gideon Taylor found that using GPT4-turbo as the exclusive engine for an enterprise chatbot would result in 4x-10x the cost of current methods. At that price point, most organizations won’t be rolling out pure LLM-based enterprise chatbots.
The surgical use of LLMs inside a bot is a safer and far less expensive approach, considering where we currently are in the Gen AI hype cycle.
Conclusion
Generative AI is undeniably transformative. It is imperative, though, to navigate its landscape with a clear-eyed view of its capabilities and limitations. At Gideon Taylor, we integrate these technologies with prudence, advocating for the adoption of current, reliable AI solutions while staying abreast of evolving models. Should you act now to leverage the enterprise value of AI? Yes. Will Gen AI costs decrease and functionally expand in the future? Yes. To profit from AI now without locking your enterprise out of growing Gen AI opportunity, it is paramount to partner with an AI provider who is growing with the AI landscape, and will help you leverage the practical power of AI without succumbing to or being paralyzed by the hyperbole.
In our next post we will examine how traditional AI works compared to Generative AI and what it takes to implement and manage both. Should you have any thoughts or questions, we would love to hear from you! Just click the Contact Us button below.